SLAC Science + Stanford AI: Bridging the Farm

Name:
SLAC Science + Stanford AI: Bridging the Farm
Date:
Tuesday, February 9, 2021
Location:
Virtual
Overview:
The Machine Learning Initiative at SLAC is pleased to announce the first annual mini-workshop aimed at creating connections between Stanford AI researchers and SLAC scientists.
The goal of this workshop is to join the Stanford Artificial Intelligence community (data science, advanced analytics, and machine learning) with SLAC researchers across the natural sciences: physics, chemistry, biology, materials science, and more. SLAC’s science missions have unique strengths in large-scale experiments, which means SLAC scientists have a wide variety of large datasets well-suited to AI exploration. This workshop will foster relationships between Stanford and SLAC to create new collaborations, and push forward both scientific knowledge and algorithmic development.
On the SLAC side, we invite participation from researchers with large data sets, complex simulations, or challenging control problems. The emphasis will be on scientific problems that are already well-defined and ready for AI-solutions: i.e. data sets already in-hand and/or simulations already in-use. On the Stanford side, we invite participation from researchers in relevant areas of AI, and with a deep interest in the physical sciences. We are not looking for a simple exchange of data or algorithms but seek to empower computer scientists and domain scientists to work hand-in-hand to tackle problems at the edge of scientific AI.
The format of the workshop will focus on making personal connections. There will be a 1-2 hour session of lightning talks from both AI and Science experts to introduce areas of interest. This will be followed by two different virtual poster sessions: one poster session will exhibit research from science experts and one will exhibit research from AI experts. Both poster sessions will be arranged to emphasize cross-domain discussion.
Agenda:
8:30AM : Introductory Remarks
8:50AM : Lightning Talks Session I
- Jana Thayer (LCLS)
- Auralee Edelen (Particle Accelerator)
- Risa Wechsler (Cosmic Frontier)
- Wah Chiu (CryoEM)
- Serena Yeung (Biomedical Data Science)
- Gustavo Cezar (GISMo Lab)
9:25AM : Break
9:40AM : Lightning Talks Session II
- Chelsea Finn (Computer Science + Electrical Engineering)
- James Zou (Biomedical Data Science)
- Mykel Kochenderfer (Aeronautics and Astronautics)
- Gordon Wetzstein (Electrical Engineering)
- Laurel Orr (Computer Science)
- Stefano Ermon (Computer Science)
Poster Sessions
Presenter: Micah Buuck
Abstract: The MeV-scale gamma-ray sky is poorly measured compared to nearby energy ranges. There are a number of interesting astrophysical sources at that energy that can be measured with a type of detector that has not previously been used in space: a time-projection chamber (TPC). A TPC can have superior position resolution of gamma rays inside the detector, creating the possibility of locating a gamma-ray source on the sky. Gamma-ray interactions create tracks of scattered electrons inside the detector, which take random paths while losing their kinetic energy to the detector material. Determining the initial electron scatter position and direction is a task well-suited for deep learning techniques, and we show here work done on this project so far.
Presenter: Robert Tang-Kong
Abstract: SSRL is a multi user facility that tackles a variety of characterization problems from users across the country. As we are able to collect more data, we are faced with a pressing need to more quickly understand that data. In short, there is a gap between the measurements we take and knowledge we are looking for. ML/AI methods provide a promising solution to this problem. We present two examples of problems where we think ML could help close this gap: X-ray Diffraction and X-ray Spectroscopy.
Presenter: Tailin Wu
Abstract: SLAC's petawatt (PW) laser upgrade at MEC/LCLS will address important grand challenges in FES and related DOE areas, including particle acceleration in high-energy-density plasmas, studying properties of warm dense matter and fusion materials, etc.. High-precision, first principles simulations are crucial for understanding the dynamics of these systems. However, such large-scale simulations are computationally intensive, requiring massive computing resources which often become infeasible for direct modeling of realistic experimental conditions. Nevertheless, there is usually the presence of dominant, low-dimensional coherent structures, suggesting the possibility of efficiently describing the system in a latent space with much lower dimensions. Here we propose utilizing sparse regression and dimensional reduction via deep autoencoders to accelerate the computation for these large, nonlinear dynamical systems, aiming to incorporate fundamental symmetries in the machine learned representations and ensure physical consistency, accuracy and generalizability.
Presenter: Sathya Chitturi
Abstract: X-ray diffraction (XRD) techniques provide a wealth of structural information on materials. Interpretation of this data can be time consuming, and preclude the rapid feedback of results into real time experimental refinement. Our group has focused on the automation of this data analysis step, and the incorporation of this analysis into real time experimental design. We shall present our progress on the development of convolutional neural networks which can take raw XRD patterns and produce estimates for lattice parameters with a mean percentage error of approximately 10%. We shall also discuss a SAXS data fitting pipeline, and demonstrate how it can be coupled to Gaussian Process Optimization to predict synthetic parameters in a closed loop that drastically accelerates discovery of new materials. Other potential datasets suitable for machine learning applications will be highlighted.
Presenter: Jesus Galaz-Montoya
Abstract: Cryo electron tomography (cryoET) can directly visualize biochemically-purified macromolecular complexes in vitro or cellular specimens (containing macromolecular complexes in situ) without using chemical fixation or staining or fluorescent fusion tags. Specimens are vitrified (flash-frozen) on cryoEM support grids (~3 mm in diameter), a metallic mesh most commonly made of copper or gold overlaid with a thin “holey” carbon film. The specimens are then imaged in an electron microscope with one of the first steps being a “screening” of the grids to localize areas that contain the specimen of interest in good conditions. Each suitable area is visualized from multiple directions by rotating the specimen stage about the “tilt axis”, typically from -60° to +60°, in 1° to 3° tilt increments.
At each tilt angle, ~10 noisy, low-contrast images (~4k x 4k pixels in size) are recorded in low-dose “movie mode” with a direct electron detector. The dose must be kept low to minimize radiation damage from the electron beam. These “movie stacks” are computationally aligned, filtered (dose-weighted), and averaged iteratively in 2D to compensate for beam-induced blurring, to obtain a single, averaged image at each tilt angle with improved signal-to-noise ratio, allowing to more accurately correct for an artifact called the Contrast Transfer Function and achieve higher resolutions.
The collection of images across tilt angles is called a “tilt series” (121 images of ~4k x 4k pixels per tilt series when a 1° tilt step is used), similar to CT scans or MRIs in medical imaging. These images are aligned computationally to their common tilt axis and combined in 3D through “tomographic reconstruction” to obtain the 3D structure or a “tomogram” of the specimen (~4k x 4k x 1k voxels per tomogram), at resolutions of tens of nanometers (~20-100 nm), depending on the sample and data collection and processing parameters. Noisy, low-contrast cryoET tomograms often contain a diversity of features that need to be annotated and assigned to classes for ease of interpretation and visualization. The process is usually done on downsampled tomograms (~1k x 1k x 250 voxels per tomogram) and is laborious, subjective, and error prone when done manually, slice by slice. While modern methods with neural networks partially automate the process and reduce the timeframe of the task from days to hours, they still suffer from high false positive and false negative rates, likely due to training the neural nets with 2D slices, as opposed to truly annotating the tomograms in 3D. Often, tomograms contain repeating features, e.g., multiple copies of macromolecular complexes, which can be identified and extracted as “subtomograms” for further analysis (~300 x 300 x 300 voxels per subtomogram). Manual identification of thousands of subtomograms is laborious, and current “template matching” approaches are not widely applicable. Subtomogram averaging can then iteratively align, classify, and average subtomograms to improve the resolution with which features are visualized, down to near-atomic resolution (~3.5 Å) in the best demonstrated cases. Given that each specimen requires multiple experiments to collect tens, hundreds, or thousands of tilt series and reconstruct the corresponding number of tomograms, from which hundreds of thousands of subtomograms can be extracted, cryoET + STA is a “big data” problem primed for automation and machine learning/artificial intelligence applications, from eliminating “bad data” at various steps to optimizing quality and reducing human intervention and bias.
Presenter: Vivek Thampy
Abstract: X-ray diffraction (XRD) techniques provide a wealth of structural information on materials. Interpretation of this data can be time consuming, and preclude the rapid feedback of results into real time experimental refinement. Our group has focused on the automation of this data analysis step, and the incorporation of this analysis into real time experimental design. We shall present our progress on the development of convolutional neural networks which can take raw XRD patterns and produce estimates for lattice parameters with a mean percentage error of approximately 10%. We shall also discuss a SAXS data fitting pipeline, and demonstrate how it can be coupled to Gaussian Process Optimization to predict synthetic parameters in a closed loop that drastically accelerates discovery of new materials. Other potential datasets suitable for machine learning applications will be highlighted.
Presenter: Chuck Yoon
Abstract: Protein structure determination is critical for understanding biological processes and accelerating drug discovery. The X-ray free electron laser (XFEL) at LCLS has advanced two cutting-edge structure determination methods; single-particle imaging (SPI) and serial femtosecond crystallography (SFX). These X-ray pulses enable both capturing signal from samples too small to study by other techniques and outrunning radiation damage that can destroy dose-sensitive proteins. However, these novel experiments also present unprecedented data analysis challenges. Solving protein structures from LCLS data requires identifying the useful “single-hit” diffraction images from massive datasets, determining their relative orientations, and inferring the phases of the merged data. We envision three avenues where AI could complement or replace current algorithms to make an immediate impact on SPI and SFX data processing. First, deep learning could efficiently identify the single-particle “hits” used in downstream analysis and automate the removal of unwanted multi-particle and empty hits. Second, AI could accelerate orientation determination for SPI data, a critical step toward generating a map of the complete diffraction volume. Third, this orientation determination could be extended to SFX data, in which the nanocrystal cell constants must be inferred as well. Overcoming these bottlenecks in SPI and SFX data processing would dramatically accelerate data processing and potentially provide on-the-fly feedback during these exciting experiments.
Presenter: Jason Chou
Abstract: SLAC's petawatt (PW) laser upgrade at MEC/LCLS will address important grand challenges in FES and related DOE areas, including particle acceleration in high-energy-density plasmas, studying properties of warm dense matter and fusion materials, etc.. High-precision, first principles simulations are crucial for understanding the dynamics of these systems. However, such large-scale simulations are computationally intensive, requiring massive computing resources which often become infeasible for direct modeling of realistic experimental conditions. Nevertheless, there is usually the presence of dominant, low-dimensional coherent structures, suggesting the possibility of efficiently describing the system in a latent space with much lower dimensions. Here we propose utilizing sparse regression and dimensional reduction via deep autoencoders to accelerate the computation for these large, nonlinear dynamical systems, aiming to incorporate fundamental symmetries in the machine learned representations and ensure physical consistency, accuracy and generalizability.
Presenter: Jack Hirschman
Abstract: The next generation of high-brightness X-ray free electron lasers (XFEL), such as SLAC's LCLS-II, promises to address current challenges associated with systems with low X-ray cross-sections. A key component is the photoinjector, which produces the electron beams whose phase-space determines the performance of the XFEL [1]. Active e-beam manipulation techniques and diagnostics are required in order to fully capitalize on this new generation of XFELs. Here, we explore a possible solution for adaptive e-beam shaping using a hardware-based machine learning implementation of real-time photoinjector laser manipulation with the penultimate goal of feeding back X-ray pulses to the photoinjector for active tuning.
[1] Penco, G., et al. "Experimental demonstration of electron longitudinal-phase-space linearization by shaping the photoinjector laser pulse." Physical review letters 112.4 (2014): 044801.
Presenter: Bruis van Vlijmen
Abstract: Li-ion battery cells are complex systems which behavior depends on phenomena that occur largely spectrum of length and time scales – a behavior of a system that changes non-linearly over time and not yet possible to model accurately. When a battery degrades the performance of the battery is impact two-fold, (1) it loses its ability to store energy, i.e. capacity loss, (2) its capability to deliver high power is diminished. When these 2 metrics drop below a certain threshold, industry deems them as dead, they have reached their End Of Life (EOL). We want to know when this will happen, very early in a cell’s life (before its onset).
At SLAC’s new Battery Informatics Lab, we’re currently gathering the world’s largest public cell degradation dataset of its kind. Can we leverage ML or advanced data analytics to detect early cell degradation or critical safety events?
Presenter: Kaiming Zhang
Abstract: Breakthroughs in single-particle cryo-electron microscopy (cryo-EM) technology have made near-atomic resolution structure determination possible. Here, we report a ~1.35-Å structure of apoferritin reconstructed from images recorded on a Gatan K3 or a Thermo Fisher Falcon 4 detector in a 300-kV Titan Krios microscope (G3i) equipped with or without a Gatan post-column energy filter. Our results demonstrate that the atomic-resolution structure determination can be achieved by single-particle cryo-EM with a fraction of a day of automated data collection. These structures resolve unambiguously each heavy atom (C, N, O, and S) in the amino acid side chains with an indication of hydrogen atoms’ presence and position, as well as the unambiguous existence of multiple rotameric configurations for some residues. We also develop a statistical and chemical based protocol to assess the positions of the water molecules directly from the cryo-EM map. In addition, we have introduced a B’ factor equivalent to the conventional B factor traditionally used by crystallography to annotate the atomic resolution model for determined structures. Our findings will be of immense interest among protein and medicinal scientists engaging in both basic and translational research.
Presenter: Ryan Coffee
Abstract: We present three current projects that span scientific domains yet share functional similarity for processing of sensor data: magnetic plasma confinement (DOE-FES), attoclock spectroscopy (DOE-BES), and Time-Tagged radiography (NIH). There is an opportunity for synergistic development of a streaming transformation pipeline from analog sensor signals into information dense representations.
Presenter: Naoufal Layad
Abstract: Free-electron lasers providing ultra-short X-ray pulses have great potential for a wide impact on science. To fully exploit this potential, we need to make accurate and efficient X-ray diagnostics which are very essential for LCLS; they provide a means of investigating a wide variety of interesting phenomena and optimizing the LCLS performance. We are working on the upgrade of the CookieBox angular streaking detector system. This system reconstructs the X-ray pulses using time-of-flight detectors. The goal of this project is developing new probabilistic and deep learning models to infer the energy-angle dependent probability density function of electrons' energy. We will solve this challenge with and without using a circularly polarized optical laser field in the interaction region.
Presenter: Sebastian Wagner-Carena
Abstract: Strong gravitational lenses are directly sensitive to the large-scale structure along the line of sight, and the metric of the Universe. These are the very regimes where some of the most interesting questions about the nature of dark matter and the geometry of our universe can be probed. The upcoming order of magnitude increase in the size of our strong lensing datasets will challenge our traditional modeling tools and require techniques that can provide statistically consistent posteriors for thousands of images. Here, we explore BNNs with flexible posterior parameterizations and incorporate them into a hierarchical inference framework that allows for the reconstruction of population hyperparameters.
Presenter: Peter Dahlberg
Abstract: Cryogenic electron tomography (CET) provides rich three-dimensional datasets of biological structures such as whole cells, or cellular fragments. Contained within these datasets can be thousands of different molecular species. A current challenge in the field of CET is the direct identification of small (<100 kDa) biomolecules in these volumes. Currently, there are limited labelling strategies compatible with CET. To overcome this limitation, we have developed a correlative microscopy approach that uses the specific labelling strategies of super-resolution fluorescence microscopy conducted at cryogenic temperatures to identify any biomolecule of interest in CET reconstructions with a lateral accuracy and precision of ~30 nm and ~10 nm respectively. Our method, correlative imaging by annotation with single molecules (CIASM), is currently being used to identify the subcellular locations of specific proteins of interest to answer biological questions. At this poster I will discuss one of these biological applications and the details of the information that our method provides. In the context of the SSAI meeting, our method could be used to provide ground truth information to validate new computational methods that identify molecular species of interest.
Presenter: Apurva Mehta
Abstract: SSRL is a multi user facility that tackles a variety of characterization problems from users across the country. As we are able to collect more data, we are faced with a pressing need to more quickly understand that data. In short, there is a gap between the measurements we take and knowledge we are looking for. ML/AI methods provide a promising solution to this problem. We present two examples of problems where we think ML could help close this gap: X-ray Diffraction and X-ray Spectroscopy.
Presenter: Richard Walroth
Abstract: X-ray diffraction (XRD) techniques provide a wealth of structural information on materials. Interpretation of this data can be time consuming, and preclude the rapid feedback of results into real time experimental refinement. Our group has focused on the automation of this data analysis step, and the incorporation of this analysis into real time experimental design. We shall present our progress on the development of convolutional neural networks which can take raw XRD patterns and produce estimates for lattice parameters with a mean percentage error of approximately 10%. We shall also discuss a SAXS data fitting pipeline, and demonstrate how it can be coupled to Gaussian Process Optimization to predict synthetic parameters in a closed loop that drastically accelerates discovery of new materials. Other potential datasets suitable for machine learning applications will be highlighted.
Presenter: Joseph Duris
Abstract: Particle accelerators require adjustment of system settings to control the final electron beam characteristics for different applications. At present, this optimization process is often done manually by human operators by visual inspection. Electron beam transport can involve collective effects, making their control non-intuitive for human operators. Online optimization methods that directly compare images of the electron beam to a desired target distribution have shown promising results for returning to previous setups. We desire methods for automatically tuning novel setups.
Presenter: Ji Won Park
Abstract: Strong gravitational lensing is a valuable probe of the Hubble Constant (H0), fully independent of other probes. Seven lenses have been “hand-analyzed” over a 10-year program [1] but the Rubin Observatory Legacy Survey of Space and Time (LSST) will discover thousands more [2]. We use Bayesian neural networks (BNN) to rapidly model a simulated set of 200 lenses and propagate the resulting posterior PDFs toward H0 inference. A simple combination of the lenses results in a precise (0.7%) recovery of the input truth H0, with no evidence of bias. Being accurate and efficient, the BNN pipeline is a promising tool for including all the lenses in large-scale hierarchical inference.
Presenter: Juhao Wu
Abstract: Alzheimer’s Disease (AD), the most common type of dementia and one of the leading causes of death in America, impairs memory and other important cognitive functions. Studies show that Alzheimer’s cases can be reduced by up to 50% if the average age of onset of this disease is delayed by 5 years, which can be done through early diagnosis and treatment.
Currently, various costly and time consuming tests have to be run before AD diagnosis can be confirmed. We would like to develop a new method to diagnose each stage of AD faster, more cost-effective and accurate by combining the bio-imaging and genetic testing information.
Presenter: Jeffery Gu
Abstract: Given the current pandemic, understanding the biology of coronaviruses is a very important topic. Cryogenic electron tomography allows the imaging of viruses in their natural state, but processing these images at scale is difficult and time-consuming for humans. Machine learning approaches such as (semi)-supervised segmentation can alleviate this problem. This allows us to answer various biological questions about the virus in a large-scale way, such as the size of virus particles, the number of virus spikes per virus particle, the distribution of virus spikes on the virus particle, and the distribution of the angles of the virus spike relative to the virus body. We propose a segmentation framework that automatically segments cryo-ET virus particles.
Presenter: Julien Martel
Abstract: SIREN: Implicit Representation with Periodic Activation Functions Emerging neural implicit representations are a promising alternative to conventional discrete signal representations. Instead of spatial resolution, their memory scales with signal complexity, and their continuity allows sampling at arbitrary resolution. SIREN may fit natural signals such as images, audio signals or video directly. Derivatives match the signals'. By including constraints on derivatives of Φ in the loss function L, SIREN can be used to solve Partial Differential Equations. However, current network architectures cannot model signals with fine details, and fail to represent a signal's spatial and temporal derivatives, which are critical to represent signals defined as the solution to Partial Differential Equations (PDEs). We propose Sinusoidal Representation Networks, or SIRENs, to alleviate these issues using the periodic sine activation.
Presenter: Michael Xie
Abstract: Consider a prediction setting where a few inputs (e.g., satellite images) are expensively annotated with the prediction targets (e.g., crop types), and many inputs are cheaply annotated with auxiliary information (e.g., climate information). How should we best leverage this auxiliary information for the prediction task? Empirically across three image and time-series datasets, and theoretically in a multi-task linear regression setting, we show that (i) using auxiliary information as input features improves in-distribution error but can hurt out-of-distribution (OOD) error; while (ii) using auxiliary information as outputs of auxiliary tasks to pre-train a model improves OOD error. To get the best of both worlds, we introduce In-N-Out, which first trains a model with auxiliary inputs and uses it to pseudolabel all the in-distribution inputs, then pre-trains a model on OOD auxiliary outputs and fine-tunes this model with the pseudolabels (self-training). We show both theoretically and empirically that In-N-Out outperforms auxiliary inputs or outputs alone on both in-distribution and OOD error.
Presenter: Ines Chami
Abstract: Graph embedding methods aim at learning representations of nodes that preserve graph properties (e.g. graph distances). These embeddings can then be used in downstream applications such as recommendation systems. Most machine learning algorithms learn embeddings into the standard Euclidean space. Recent research shows promise for more faithful embeddings by leveraging non-Euclidean geometries, such as hyperbolic or spherical geometries. In this poster, we present two applications of hyperbolic embeddings, namely link prediction in Knowledge Graphs and hierarchical clustering.
Presenter: Joy Hsu
Abstract: We propose a method for 3D instance segmentation from sparse 2D annotations for the analysis of neuronal cells. From segmentations of the mitochondria, granule, cristae, and hairball, we analyze the differences between diseased and non-diseased cells and characterize detected components. Our supervised method with minimal annotations is applicable to all datasets, though our current work focuses on research for Huntington’s disease. We showcase results as well as potential for future work in the unsupervised learning space.
Presenter: Bennet Meyers
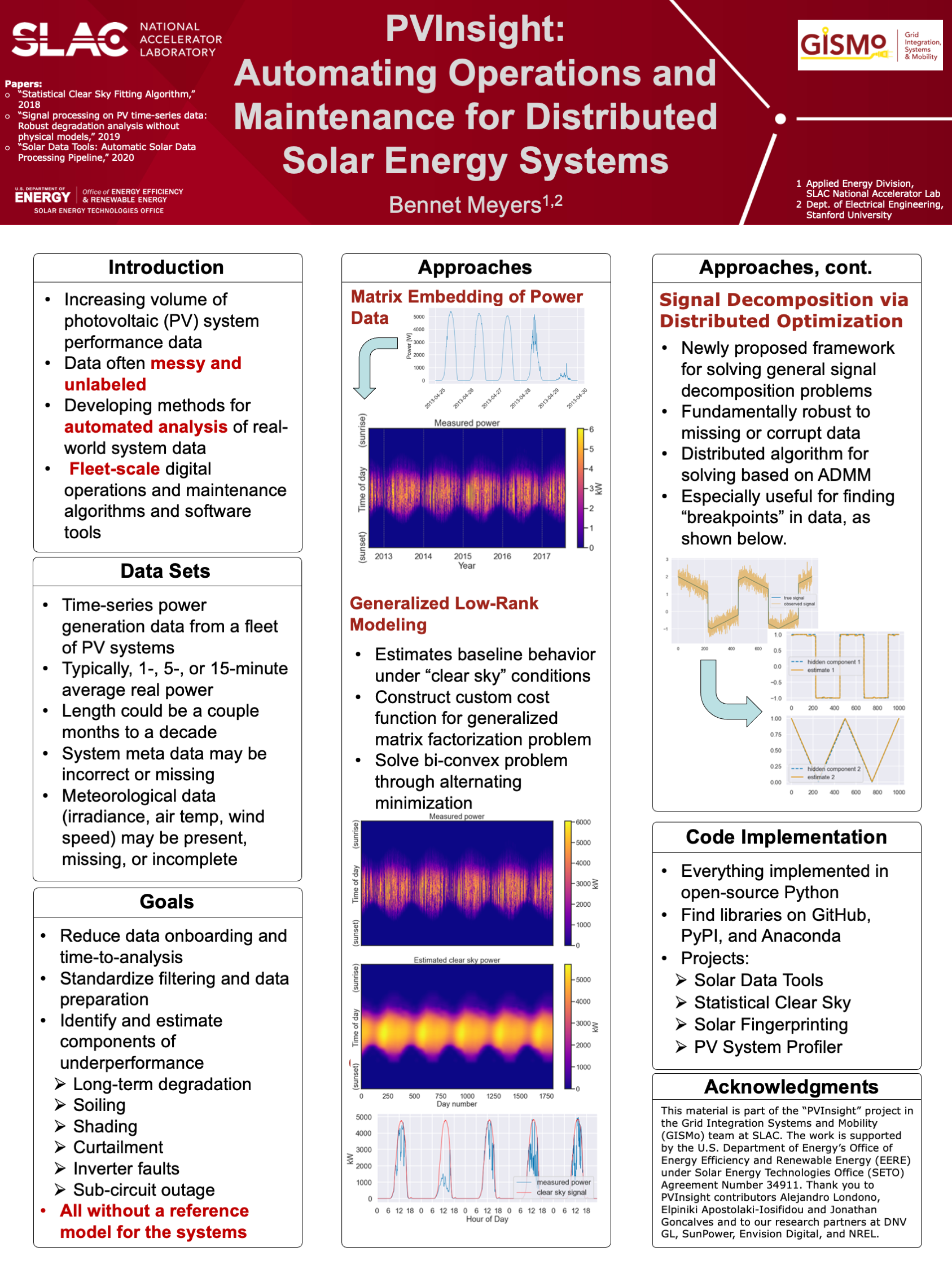
Abstract: The increasing number of distributed photovoltaic (PV) energy generation systems presents an operational challenge. For this generation resource to be valuable to the grid, it must be reliable and not suffer from correctable maintenance issues. Digital operations and maintenance (O&M) describes the backend software and analysis performed by companies who are increasingly responsible for the long-term performance of large fleets of heterogenous systems. We present a selection of statistical learning techniques that we have applied to the task of analyzing PV system performance and reliability. Labeled data sets that are sufficiently diverse are difficult to obtain for these tasks, so we primarily utilize unsupervised statistical learning and signal processing. A connecting theme in these methods is adopting a signal decomposition framework and defining prior distributions for the unobserved components. This is quite effective on tasks such as baseline estimation from noisy and incomplete data and generalized breakpoint detection, known to be a difficult combinatorial optimization problem.
{kind=link}
Presenter: Shengjia Zhao
Abstract: Distributions learned by generative models can in principle be used to estimate the expectation of any desired query function. However, in practice these estimates can be highly inaccurate, posing a challenge for downstream applications. Meanwhile, query functions can be estimated directly with standard supervised regression techniques, sacrificing generality for accuracy. In this paper, we propose an algorithm to achieve the best of both worlds: we design a set of ``basis" query functions, and learn regression functions for their expectation. At test time, we decompose a query function into the linear combination of basis functions and a residue function. We use the learned regressors to predict the expectation of the basis functions and the generative model to predict the expectation of the residue function. In the experiments we show improved accuracy in answering expectation queries for video and traffic prediction using deep generative models.
Presenter: Moses Charikar
Abstract: The fast multipole method has been heralded as one of the top 10 algorithms with the greatest influence on the development and practice of science and engineering in the 20th century. This is the workhorse of n-body simulations. Going beyond the 2d and 3d physical systems that motivated the original algorithm, applications in modern data analysis need such computations to be performed for high dimensional data. However, the fast multipole method is based on a space decomposition approach that has an exponential dependence on the dimension. Randomized algorithmic techniques have the potential to give provable guarantees in this high dimensional setting. A recently established connection to locality sensitive hashing techniques developed for nearest neighbor search has yielded efficient algorithms in high dimensions for the special case of kernel summations, e.g. for the gaussian, exponential and polynomial kernels. This suggests a number of questions for future research which would significantly enhance the applicability of the fast multipole method to high dimensional settings.
Presenter: Ismael Lemhadri
Abstract: Much work has been done recently to make neural networks more interpretable, and one obvious approach is to arrange for the network to use only a subset of the available features. In linear models, Lasso (or L1-regularized) regression assigns zero weights to the most irrelevant or redundant features, and is widely used in data science. However the Lasso only applies to linear models. Here we introduce LassoNet, a neural network framework with global feature selection. Our approach enforces a hierarchy: specifically a feature can participate in a hidden unit only if its linear representative is active. Unlike other approaches to feature selection for neural nets, our method uses a modified objective function with constraints, and so integrates feature selection with the parameter learning directly. As a result, it delivers an entire regularization path of solutions with a range of feature sparsity. On systematic experiments, LassoNet significantly outperforms state-of-the-art methods for feature selection and regression. The LassoNet method uses projected proximal gradient descent, and generalizes directly to deep networks. It can be implemented by adding just a few lines of code to a standard neural network.
Presenter: Willie Neiswanger
Abstract: We present two projects. In the first, we develop Bayesian optimization-like methods for expensive black-box functions that aim to efficiently estimate a broad set of function properties (beyond global optima) efficiently via function evaluations. We introduce a computable function property—defined as the output of an algorithm that runs on the black box function—and give procedures for inferring this property using Bayesian optimal experimental design. In the second project, we present Uncertainty Toolbox, an open source toolbox for predictive uncertainty quantification, calibration, metrics, and visualizations.
Presenter: Allan Zhou
Abstract: In convolutional neural networks, convolution layers are equivariant to input shifts, which conserves parameters and improves generalization on shift-invariant tasks such as image classification. What if we don't know the task symmetries a priori, or how manually construct the corresponding equivariant architecture? We present an approach for learning equivariances from data, without needing to design custom task-specific architectures. The intuition is that symmetry in the task induces a certain sharing of parameters in the neural network. Our method (MSR) encodes equivariances into networks by learning the appropriate parameter sharing patterns from data.
Presenter: Amirata Ghorbani
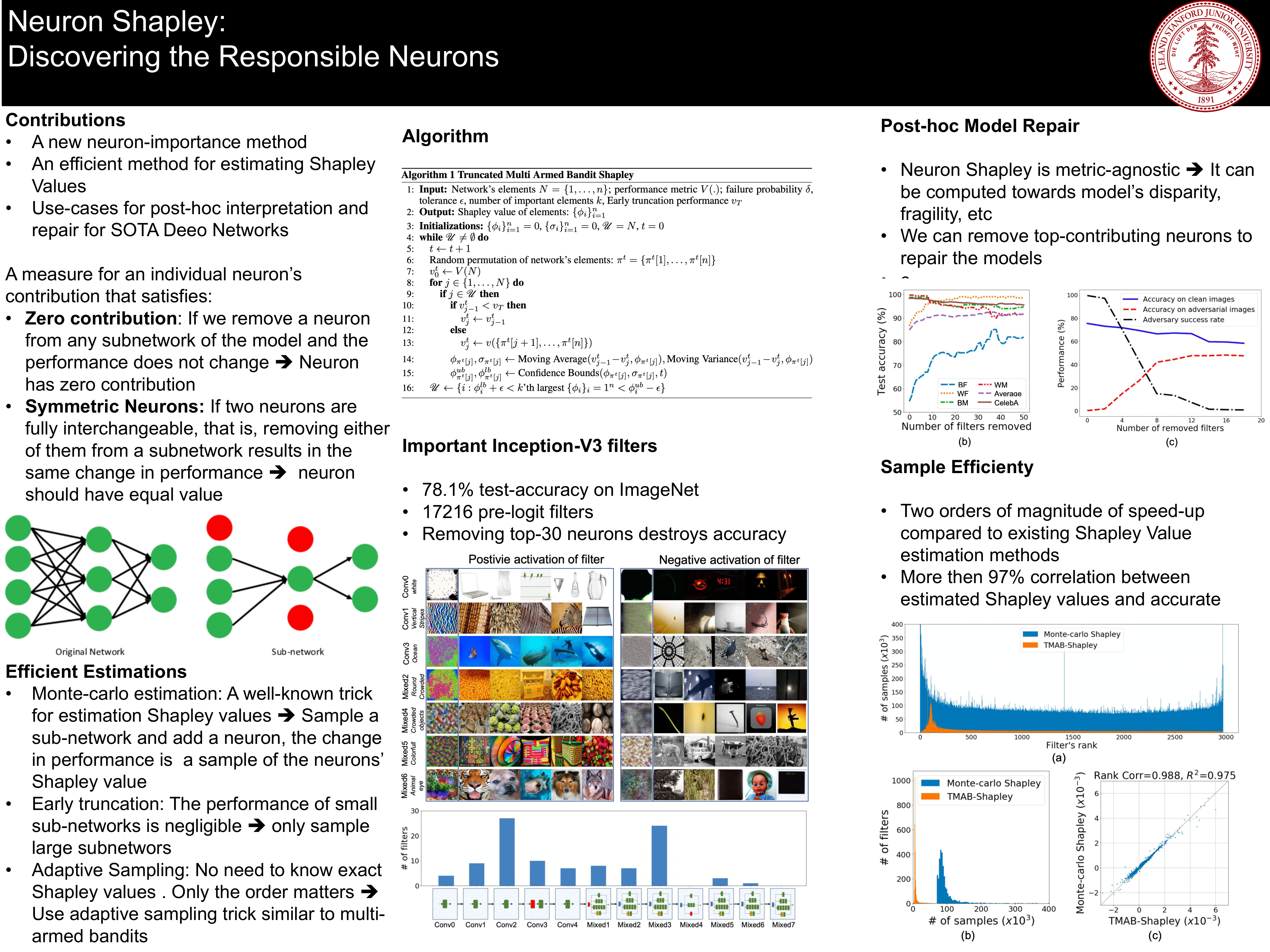
Abstract: We develop Neuron Shapley as a new framework to quantify the contribution of individual neurons to the prediction and performance of a deep network. By accounting for interactions across neurons, Neuron Shapley is more effective in identifying important filters compared to common approaches based on activation patterns. Interestingly, removing just 30 filters with the highest Shapley scores effectively destroys the prediction accuracy of Inception-v3 on ImageNet. Visualization of these few critical filters provides insights into how the network functions. Neuron Shapley is a flexible framework and can be applied to identify responsible neurons in many tasks. We illustrate additional applications of identifying filters that are responsible for biased prediction in facial recognition and filters that are vulnerable to adversarial attacks. Removing these filters is a quick way to repair models. Computing exact Shapley values are computationally infeasible and therefore sampling-based approximations are used in practice. We introduce a new multi-armed bandit algorithm that is able to efficiently detect neurons with the largest Shapley value orders of magnitude faster than existing Shapley value approximation methods.
{kind=link}
Presenter: Po-Nan Li
Abstract: We present the DeepMap, an all-neural map-to-model system for cryogenic electron microscopy (cryo-EM). Building an atomic model into a cryo-EM density map with current protocols relies on a significant amount of human inputs and can take hours to days to produce a protein model. Despite that some machine learning models have been proposed to reduce the computation time, they typically require a search algorithm to build to find the optimal output, which is still computationally intensive and do not take advantage of the graphics processing units. Here, the DeepMap is a fully automated, template-free model building pipeline that is based entirely on neural networks. We use a 3D convolutional neural network (CNN) to detect rotamers and backbone atoms, a graph convolutional network (GCN) to generate an embedding from the detected rotamer proposals, and a bidirectional long short-term memory (LSTM) to order the proposals based on the embedding and the protein sequence to obtain a structural model. We report that our model can detect 98.9% of the rotamers in our simulated high-resolution dataset with 87.5% amino acid accuracy.
Presenter: Gradey Wang
Abstract: Many current, long-standing challenges in engineering, such as wave, diffusion, and electromagnetic control problems, are approximately governed by partial differential equation are either combinatorial control problems or can be reduced to one. Combinatorial PDE-constrained optimal control problems are particularly difficult because 1) combinatorial optimization is generally computationally expensive and 2) optimizing over fields arising from PDEs can be difficult due to the lack of understanding of their behavior under nonlinear control. Motivated by applications in metal additive manufacturing and the objective of controlling the temperature history of their produced objects, we build on deep reinforcement learning techniques in order to identify high-quality control sequences for objective functions of time-dependent PDEs' field histories.
Participant List:
| LAST NAME | FIRST NAME | AFFILIATION | EXPERT DOMAIN | PERSONAL/RESEARCH WEBSITE |
|---|---|---|---|---|
| Aalbers | Jelle | KIPAC (Stanford/SLAC) | Science | link to website |
| Arora | Simran | Stanford | AI | link to website |
| Baniecki | John | SLAC/SSRL | Science | N/A |
| Betterton | Jean | Stanford University | AI | N/A |
| Bianchini | Federico | KIPAC/SLAC | Science | link to website |
| Birrer | Simon | Stanford KIPAC | Science | link to website |
| Bohler | Dorian | SLAC | Science | N/A |
| Boutet | Sebastien | LCLS | Science | N/A |
| Brodsky | Stanley | SLAC | Science | link to website |
| Burchat | Patricia | Physics Department, KIPAC, Stanford | Science | link to website |
| Buuck | Micah | SLAC | Science | N/A |
| Cai | Shawn | Stanford University | Science | N/A |
| Cezar | Gustavo | SLAC National Accelerator Laboratory | Science | link to website |
| Chami | Ines | Stanford University | AI | link to website |
| Chang | Iris | SLAC | Science | N/A |
| Charikar | Moses | Computer Science | AI | link to website |
| Chitturi | Sathya | Stanford University | Science | link to website |
| Chiu | Wah | Stanford U and SLAC | Science | link to website |
| Chou | Jason | Stanford University / SLAC | Science | N/A |
| Coffee | Ryan | LCLS/PULSE | Science | link to website |
| Dahlberg | Peter | Stanford | Science | link to website |
| Darve | Eric | Stanford | AI | link to website |
| Diaz Cruz | Jorge | SLAC | Science | N/A |
| Drielsma | Francois | SLAC | Science | N/A |
| Duris | Joseph | SLAC | Science | N/A |
| Edelen | Auralee | SLAC | Science | link to website |
| Ermon | Stefano | computer science | AI | N/A |
| Finn | Chelsea | Stanford University | AI | N/A |
| Fiuza | Frederico | SLAC | Science | N/A |
| Ghorbani | Amirata | Stanford University | AI | N/A |
| Gruen | Daniel | SLAC | Science | link to website |
| Gu | Jeffrey | ICME | AI | N/A |
| Hanuka | Adi | SLAC | Science | N/A |
| Hirschman | Jack | Stanford University/SLAC | Science | N/A |
| Hsu | Joy | Stanford University | AI | N/A |
| Hyneman | Rachel | SLAC | Science | N/A |
| Irving | Bryen | Stanford University | Science | N/A |
| Kagan | Michael | SLAC | Science | N/A |
| Kang | Daniel | Stanford University | AI | link to website |
| Kivelson | Sophia | Stanford CS department | AI | N/A |
| Kochenderfer | Mykel | Stanford University | AI | link to website |
| Layad | Naoufal | LCLS / PULSE | Science | N/A |
| Lee | Victoria | SLAC | Science | N/A |
| Lemhadri | Ismael | Stanford Statistics | AI | link to website |
| Li | Po-Nan | Stanford University | AI | link to website |
| Li | Kenan | SLAC | Science | N/A |
| Li | Yee-Ting | SLAC | Science | N/A |
| Malik | Mayank | SLAC | AI | N/A |
| Marsden | Annie | Stanford | AI | N/A |
| Marshall | Phil | SLAC | Science | link to website |
| Martel | Julien | Stanford University | AI | N/A |
| Martinez | Todd | SLAC / Stanford | Science | link to website |
| Megias i Homar | Guillem | Stanford PhD studet | Science | N/A |
| Mehta | Apurva | SSRL | Science | N/A |
| Meyers | Bennet | Applied Energy Division, SLAC | Science | N/A |
| Montoya | Jesus | Stanford | Science | N/A |
| Monzani | Maria Elena | SLAC National Accelerator Laboratory | Science | link to website |
| Na | Xieyu | SLAC | Science | N/A |
| Nashed | Youssef | SLAC | AI | N/A |
| Neiswanger | Willie | Stanford CS | AI | link to website |
| Orr | Laurel | Stanford | AI | link to website |
| O’Shea | Brendan | SLAC | Science | N/A |
| Park | Ji Won | KIPAC / SLAC | Science | N/A |
| Pivovaroff | Mike | SLAC | Science | N/A |
| Ponder | Kara | SLAC | Science | link to website |
| Ratner | Daniel | SLAC | Science | N/A |
| Schwartzman | Ariel | SLAC | Science | N/A |
| Song | Minghao | SLAC/IIT | Science | N/A |
| Srivastava | Megha | Stanford Computer Science | AI | link to website |
| Sun | Peihao | Stanford University | Science | N/A |
| Tanaka | Hirohisa | SLAC | Science | link to website |
| Tang | Jingyi | SLAC | Science | N/A |
| Tang-Kong | Robert | SLAC | Science | N/A |
| Terao | Kazuhiro | SLAC | Science | link to website |
| Thampy | Vivek | SLAC | AI | N/A |
| Thayer | Jana | SLAC | Science | N/A |
| Tiwari | Mo | Stanford University Computer Science | AI | link to website |
| van Vlijmen | Bruis | Cheuh Group Stanford, AED SLAC | Science | N/A |
| Wagner-Carena | Sebastian | Stanford University | Science | N/A |
| Walroth | Richard | SLAC National Accelerator Laboratory | Science | N/A |
| Wang | Gradey | Stanford University | AI | N/A |
| Wechsler | Risa | SLAC / Stanford | Science | N/A |
| Wetzstein | Gordon | Stanford | AI | link to website |
| White | Greg | SLAC | Science | N/A |
| Wornow | Michael | Stanford | AI | N/A |
| Wu | Mike | Computer science at stanford | AI | link to website |
| Wu | Tailin | Stanford CS | AI | link to website |
| Wu | Juhao | SLAC | Science | N/A |
| Xie | Sang Michael | Stanford | AI | link to website |
| Xin | Shuo | Stanford | Science | N/A |
| Xu | Lily | Stanford University | Science | N/A |
| Yeung | Serena | Stanford University | AI | N/A |
| Yoon | Chuck | LCLS, SLAC national accelerator laboratory | Science | N/A |
| Zhang | Zhe | SLAC National Accelerator Laboratory | Science | link to website |
| Zhang | Kaiming | Stanford | Science | N/A |
| Zhao | Shengjia | Computer Science, Stanford University | AI | link to website |
| Zhou | Guanqun | SLAC-AD | Science | N/A |
| Zhou | Allan | stanford cs | AI | link to website |
| Zhu | Henry | Stanford AI Lab | AI | link to website |
| Zou | James | Stanford University | AI | N/A |